Portfolio 2
The overarching aim of this project is to learn how to use a new package that is not part of the course, but which is relevant to my research. A secondary aim (though not an initially intended one) is to learn more about github, what differentiates sub-folders in a repository from repositories themselves, what a .git folder is, etc.
More specifically in terms of the first goal, the first aim is to learn to use the TOSTER R package for doing equivalence tests (see Lakens, 2017), https://osf.io/q253c/. I will be using some data from a study with a former graduate student (Bridget Hayes) for an article we’re working on (currently has an R&R). I don’t intend to publish this analysis – I’m just trying to get an intuitive sense of how large a difference might exist given that we found no evidence of one. Thus the second aim of the first goal is to learn how to read in data that wasn’t provided to me. The end result will hopefully be an equivalence test on a portion of our data.
Load packages and data
library(TOSTER)
library(tidyverse) display <- read_csv("p02/data/display_type.csv")options(scipen = 999)Note there are two dependent variables that I’m working with for this project: gist risk perception, and verbatim risk perception.
toster_inputs_gist <- display %>%
group_by(display_condition) %>%
summarize(mean = mean(gist_p, na.rm = TRUE), sd = sd(gist_p, na.rm = TRUE), n = sum(!is.na(gist_p)))toster_inputs_verbatim <- display %>%
group_by(display_condition) %>%
summarize(mean = mean(Average_Z_LN_plusone_verb_items, na.rm = TRUE),
sd = sd(Average_Z_LN_plusone_verb_items, na.rm = TRUE),
n = sum(!is.na(Average_Z_LN_plusone_verb_items)))Examining small, small-medium, and medium effect sizes, using Cohen’s classification from ages ago
#df_tost<- toster_inputs_gist
#loweq <- -.3
#tsum_TOST(m1 = df_tost$mean[1], m2 = df_tost$mean[2], sd1 = df_tost$sd[1], sd2 = df_tost$sd[2], n1 = df_tost$n[1], n2 = df_tost$n[2], low_eqbound = -.30, high_eqbound = 0.30, alpha = 0.05, var.equal = FALSE,eqbound_type="SMD")
#tsum_TOST(m1 = df_tost$mean[1], m2 = df_tost$mean[2], sd1 = df_tost$sd[1], sd2 = df_tost$sd[2], n1 = df_tost$n[1], n2 = df_tost$n[2], low_eqbound = -.30, high_eqbound = 0.30, alpha = 0.05, var.equal = FALSE,eqbound_type="SMD")
#df_tost<- toster_inputs_verbatim
tsum_TOST(m1 = toster_inputs_gist$mean[toster_inputs_gist$display_condition==1],
m2 = toster_inputs_gist$mean[toster_inputs_gist$display_condition==2],
sd1 = toster_inputs_gist$sd[toster_inputs_gist$display_condition==1],
sd2 = toster_inputs_gist$sd[toster_inputs_gist$display_condition==2],
n1 = toster_inputs_gist$n[toster_inputs_gist$display_condition==1],
n2 = toster_inputs_gist$n[toster_inputs_gist$display_condition==2],
low_eqbound = -0.30, high_eqbound = 0.30, alpha=0.05, var.equal = FALSE,eqbound_type="SMD")##
## Welch Two Sample t-test
##
## The equivalence test was significant, t(170) = -1.910, p = 2.89e-02
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 9.55e-01
## NHST: don't reject null significance hypothesis that the effect is equal to zero
## TOST: reject null equivalence hypothesis
##
## TOST Results
## t df p.value
## t-test 0.0571 170 0.955
## TOST Lower 2.0244 170 0.022
## TOST Upper -1.9102 170 0.029
##
## Effect Sizes
## Estimate SE C.I. Conf. Level
## Raw 0.033536 0.5873 [-0.9378, 1.0049] 0.9
## Hedges's g(av) 0.008669 0.1534 [-0.2411, 0.2584] 0.9
## Note: SMD confidence intervals are an approximation. See vignette("SMD_calcs").#toster_inputs_gist$mean[toster_inputs_gist$display_condition==1]
#TOSTtwo(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound_d = -0.30, high_eqbound_d = 0.30, alpha = 0.05, var.equal = FALSE)
TOSTtwo(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound_d = -0.20, high_eqbound_d = 0.20, alpha = 0.05, var.equal = FALSE)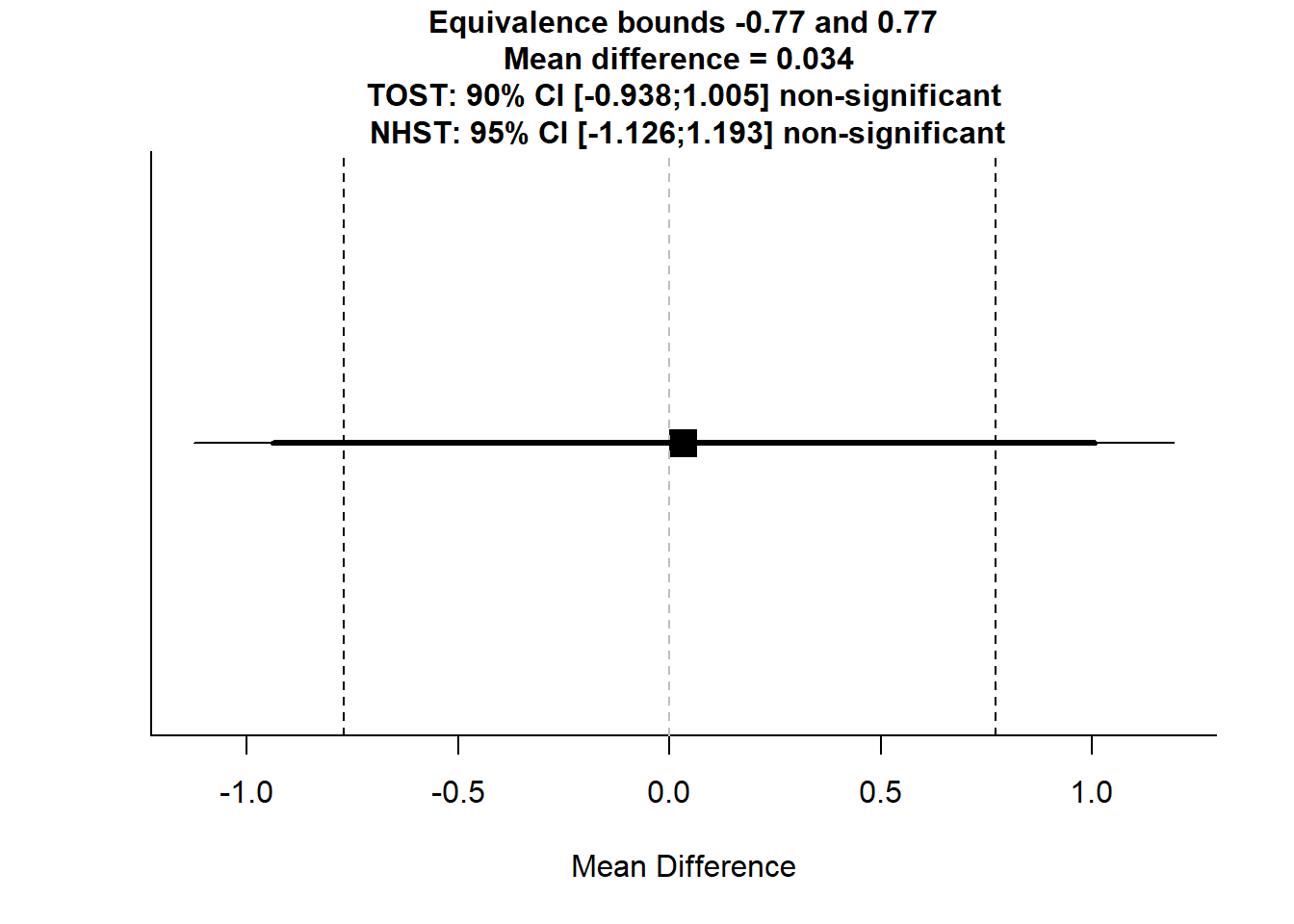
## TOST results:
## t-value lower bound: 1.37 p-value lower bound: 0.086
## t-value upper bound: -1.25 p-value upper bound: 0.106
## degrees of freedom : 170
##
## Equivalence bounds (Cohen's d):
## low eqbound: -0.2
## high eqbound: 0.2
##
## Equivalence bounds (raw scores):
## low eqbound: -0.7703
## high eqbound: 0.7703
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(170) = -1.254, p = 0.106, given equivalence bounds of -0.770 and 0.770 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.TOSTtwo(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound_d = -0.10, high_eqbound_d = 0.10, alpha = 0.05, var.equal = FALSE)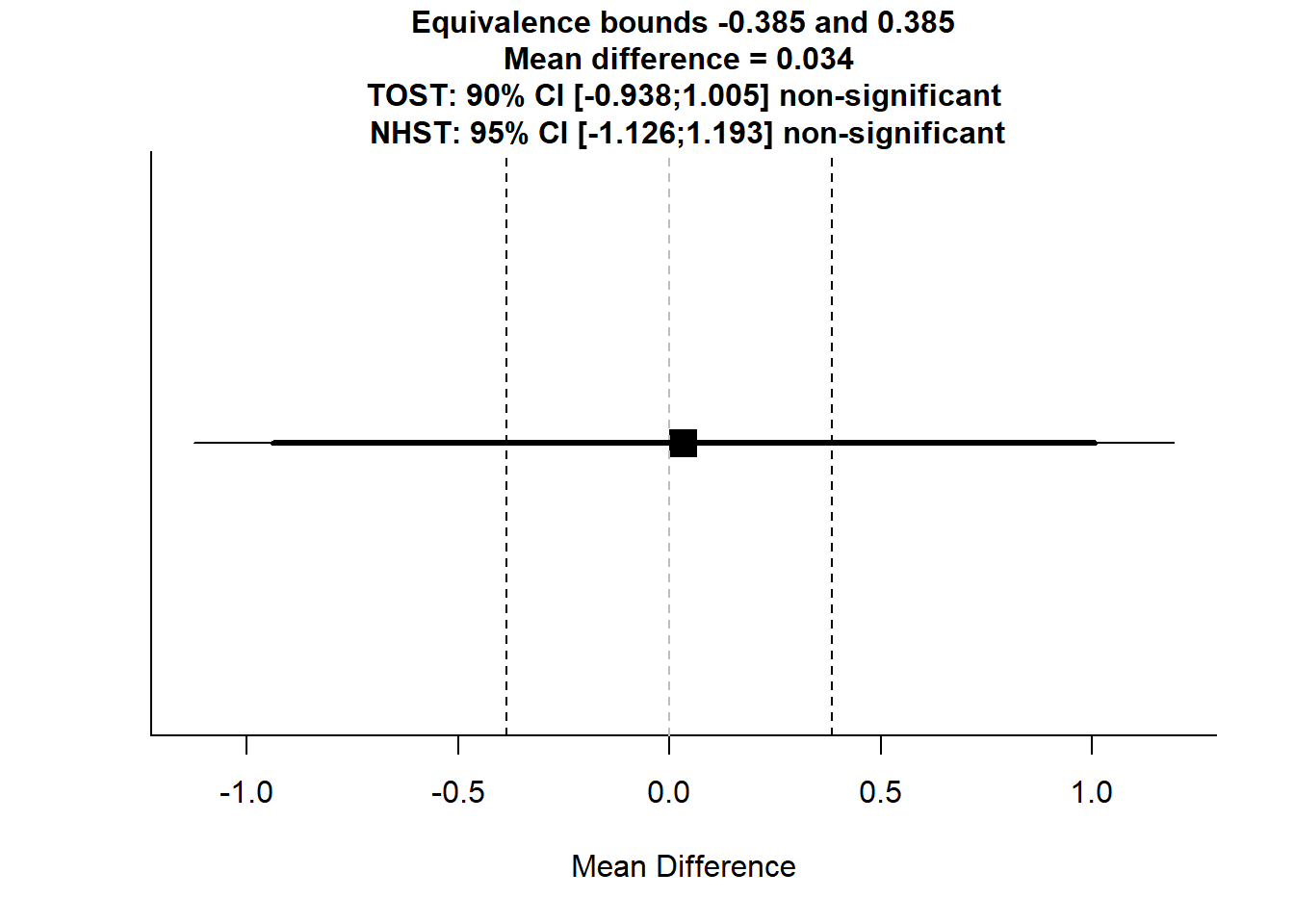
## TOST results:
## t-value lower bound: 0.713 p-value lower bound: 0.238
## t-value upper bound: -0.599 p-value upper bound: 0.275
## degrees of freedom : 170
##
## Equivalence bounds (Cohen's d):
## low eqbound: -0.1
## high eqbound: 0.1
##
## Equivalence bounds (raw scores):
## low eqbound: -0.3852
## high eqbound: 0.3852
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(170) = -0.599, p = 0.275, given equivalence bounds of -0.385 and 0.385 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.Using the raw score formula for replication and practice … (Used excel to get mean differences corresponding to the above Cohen’s d’s)
TOSTtwo.raw(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound = -1.155583283, high_eqbound = 1.155583283, alpha = 0.05, var.equal = FALSE)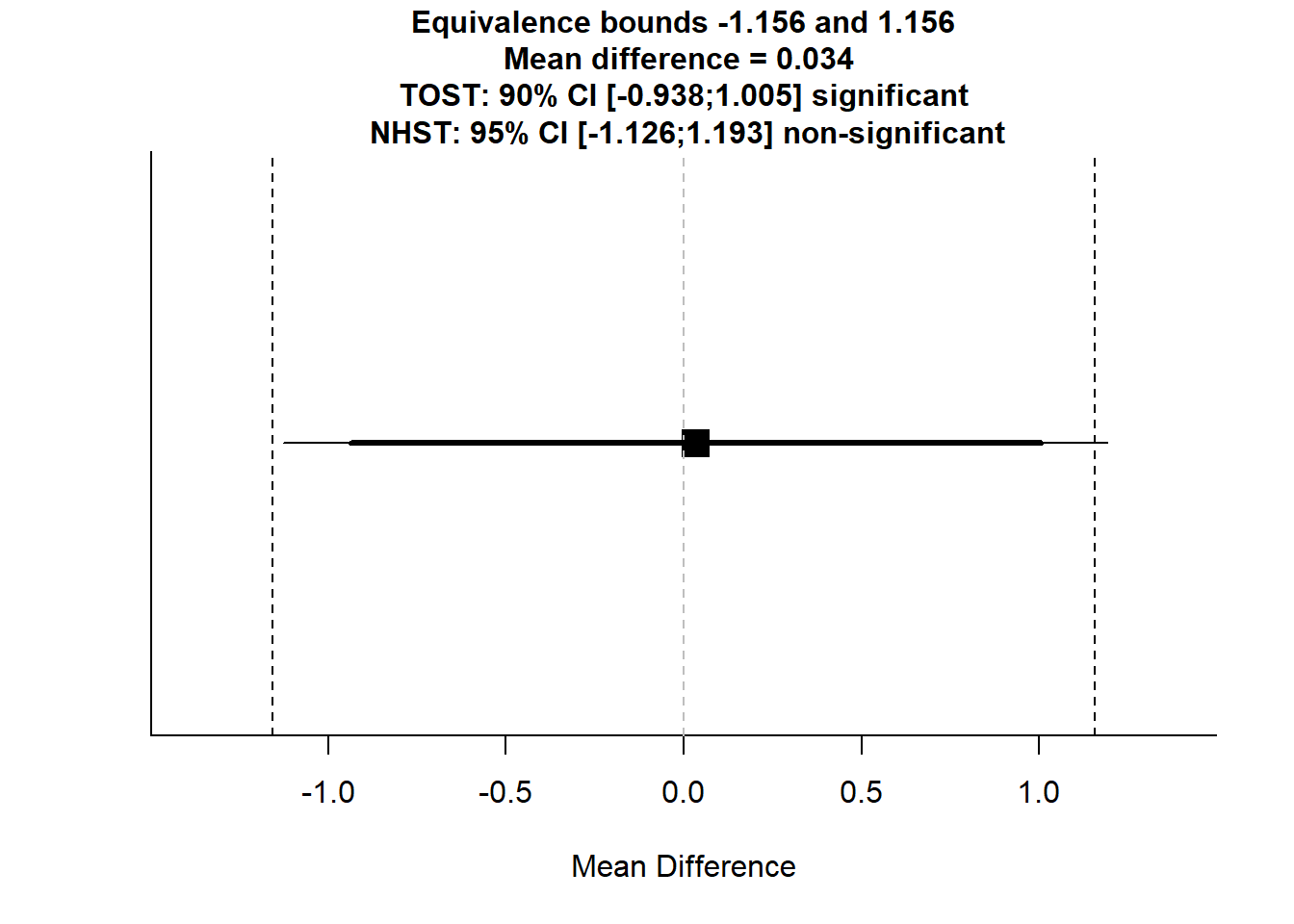
## TOST results:
## t-value lower bound: 2.02 p-value lower bound: 0.022
## t-value upper bound: -1.91 p-value upper bound: 0.029
## degrees of freedom : 170
##
## Equivalence bounds (raw scores):
## low eqbound: -1.1556
## high eqbound: 1.1556
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was significant, t(170) = -1.910, p = 0.0289, given equivalence bounds of -1.156 and 1.156 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.TOSTtwo.raw(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound = -0.770388855, high_eqbound = 0.770388855, alpha = 0.05, var.equal = FALSE)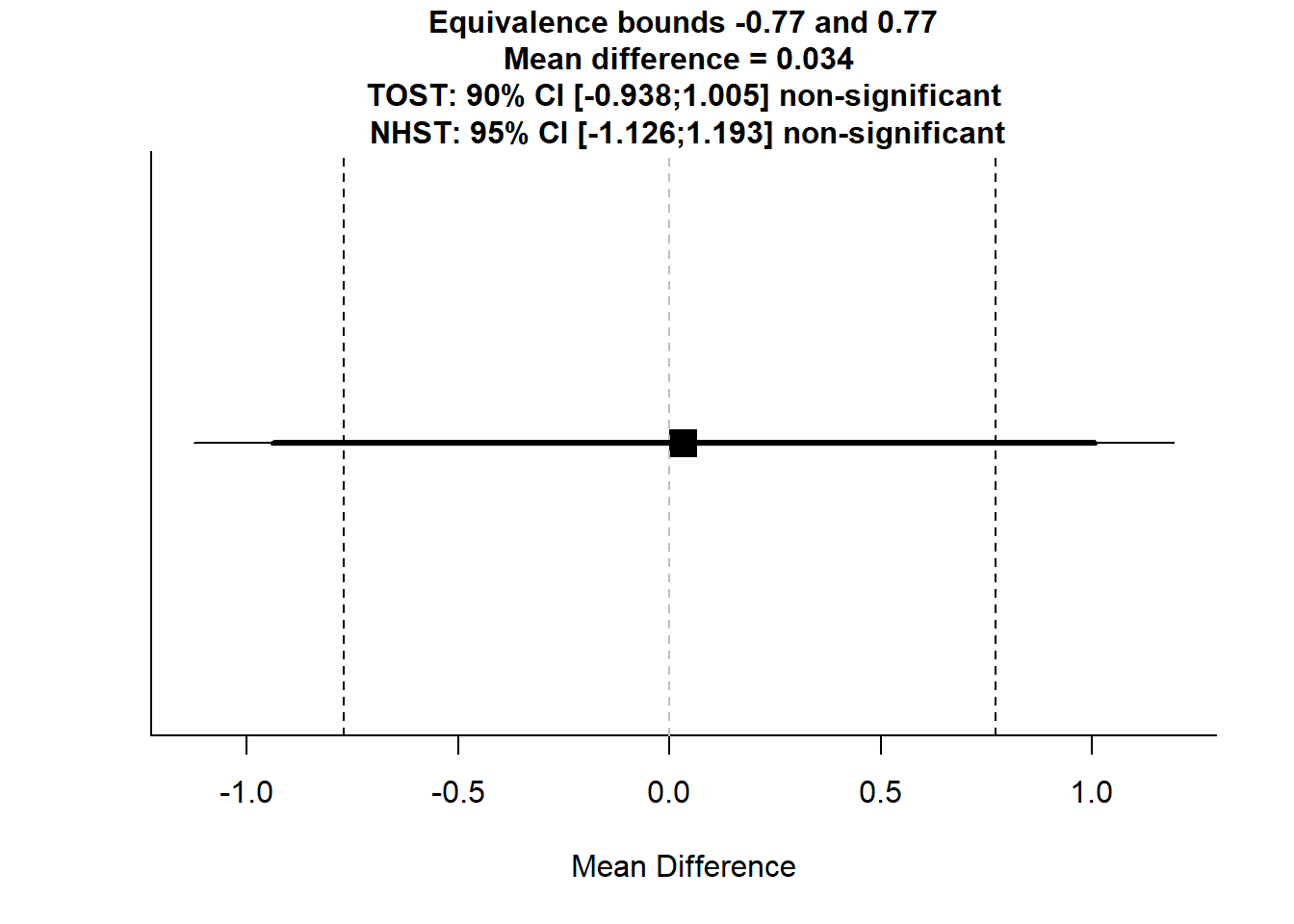
## TOST results:
## t-value lower bound: 1.37 p-value lower bound: 0.086
## t-value upper bound: -1.25 p-value upper bound: 0.106
## degrees of freedom : 170
##
## Equivalence bounds (raw scores):
## low eqbound: -0.7704
## high eqbound: 0.7704
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(170) = -1.255, p = 0.106, given equivalence bounds of -0.770 and 0.770 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.TOSTtwo.raw(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound = -0.385194428, high_eqbound = 0.385194428, alpha = 0.05, var.equal = FALSE)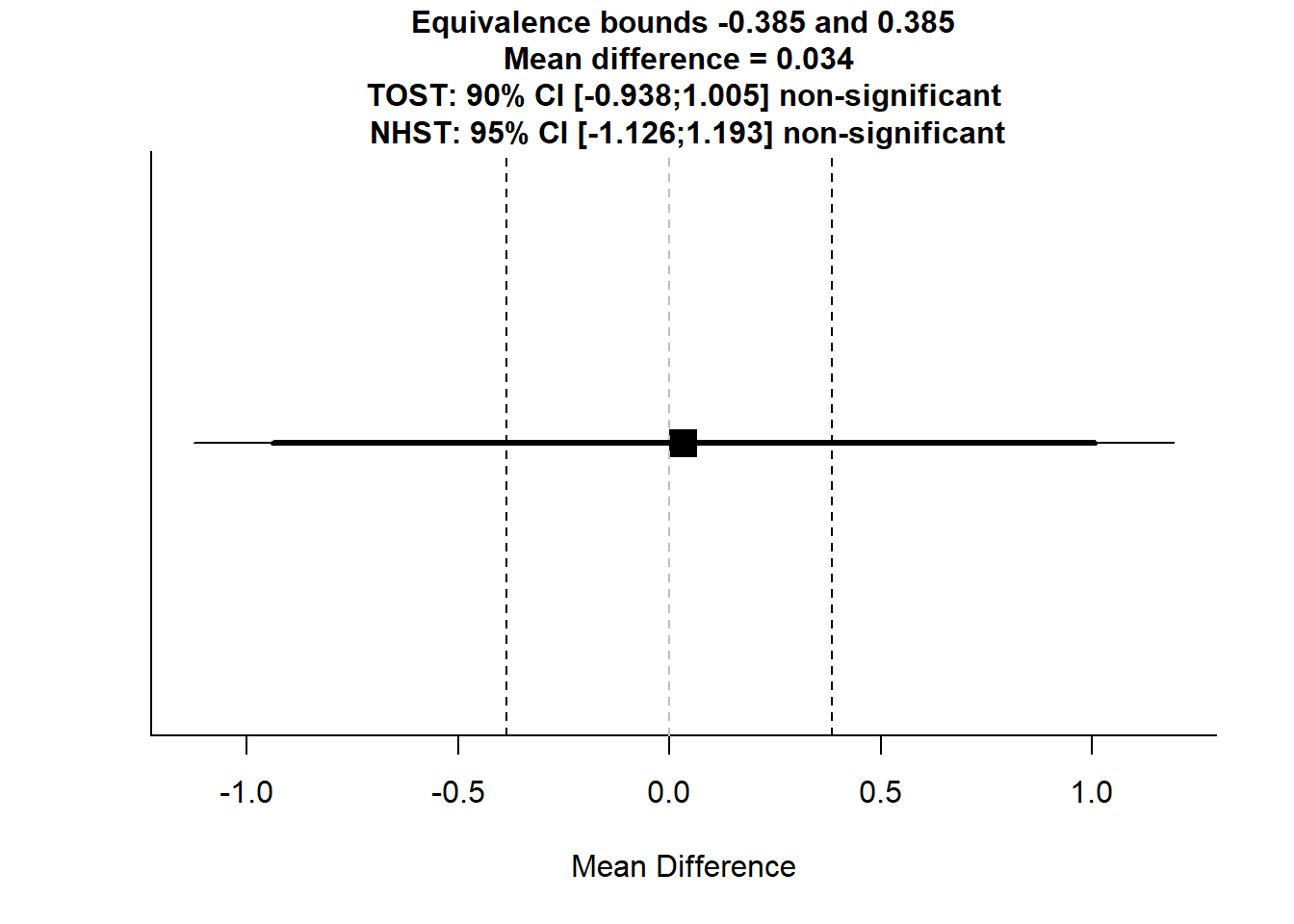
## TOST results:
## t-value lower bound: 0.713 p-value lower bound: 0.238
## t-value upper bound: -0.599 p-value upper bound: 0.275
## degrees of freedom : 170
##
## Equivalence bounds (raw scores):
## low eqbound: -0.3852
## high eqbound: 0.3852
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(170) = -0.599, p = 0.275, given equivalence bounds of -0.385 and 0.385 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.These match, thankfully. Given that, I’m only going to do the first analysis for verbatim.
TOSTtwo(m1 = -0.08914941, m2 = -0.11634700, sd1 = 0.7748390, sd2 = 0.8841862, n1 = 84, n2 = 87, low_eqbound_d = -0.30, high_eqbound_d = 0.30, alpha = 0.05, var.equal = FALSE)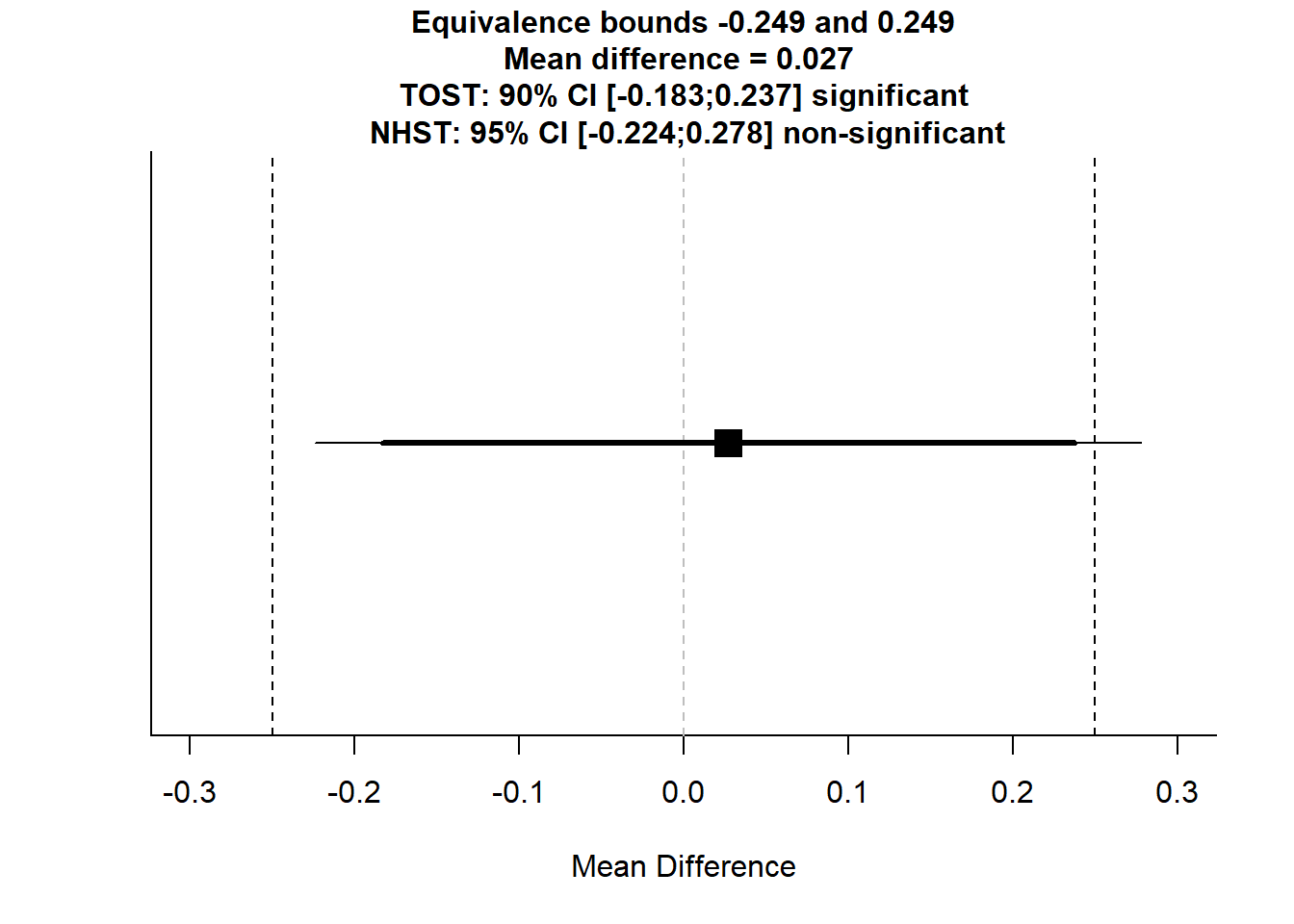
## TOST results:
## t-value lower bound: 2.18 p-value lower bound: 0.015
## t-value upper bound: -1.75 p-value upper bound: 0.041
## degrees of freedom : 167.45
##
## Equivalence bounds (Cohen's d):
## low eqbound: -0.3
## high eqbound: 0.3
##
## Equivalence bounds (raw scores):
## low eqbound: -0.2494
## high eqbound: 0.2494
##
## TOST confidence interval:
## lower bound 90% CI: -0.183
## upper bound 90% CI: 0.237
##
## NHST confidence interval:
## lower bound 95% CI: -0.224
## upper bound 95% CI: 0.278
##
## Equivalence Test Result:
## The equivalence test was significant, t(167.45) = -1.749, p = 0.041, given equivalence bounds of -0.249 and 0.249 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(167.45) = 0.214, p = 0.831, given an alpha of 0.05.TOSTtwo(m1 = -0.08914941, m2 = -0.11634700, sd1 = 0.7748390, sd2 = 0.8841862, n1 = 84, n2 = 87, low_eqbound_d = -0.20, high_eqbound_d = 0.20, alpha = 0.05, var.equal = FALSE)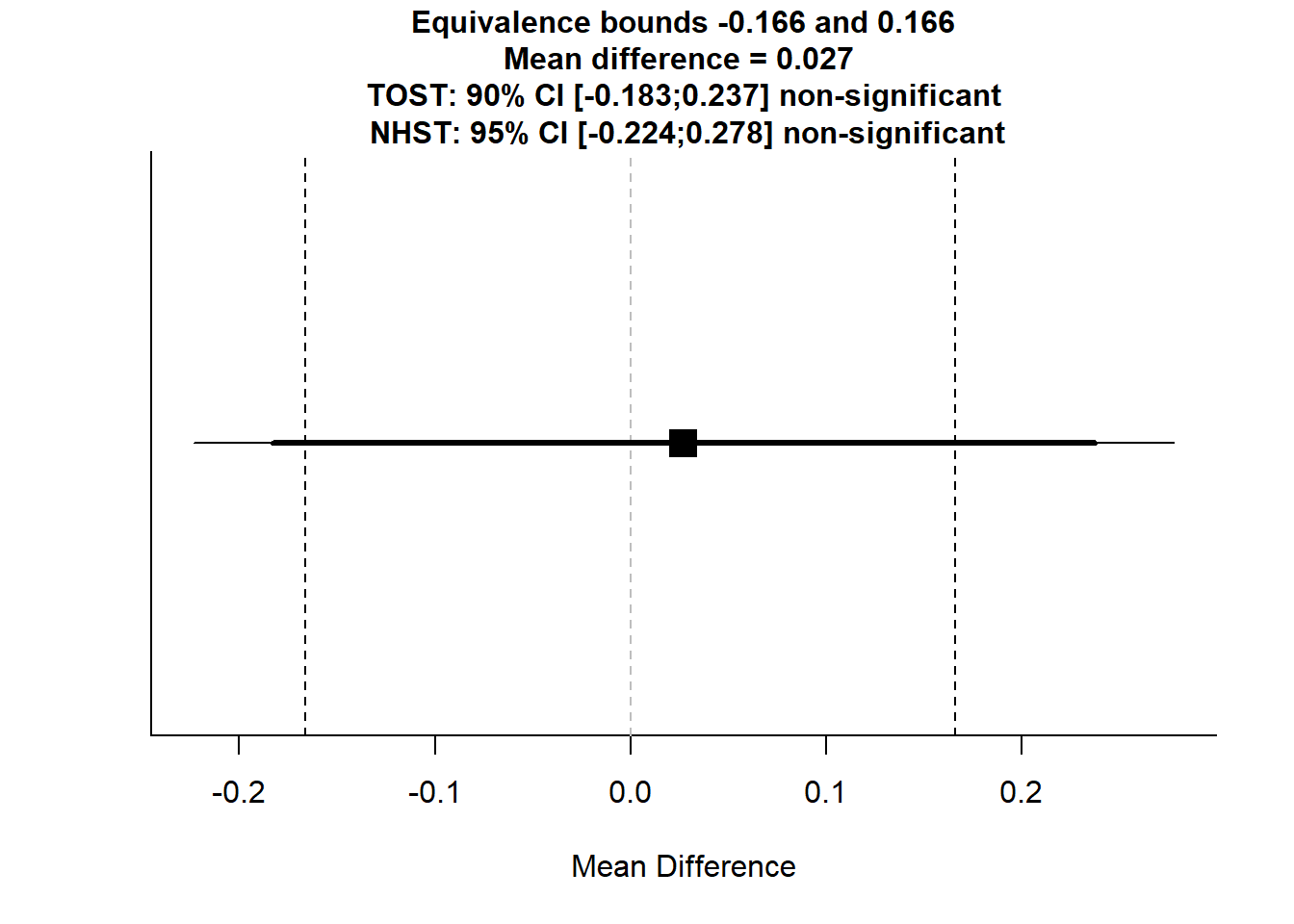
## TOST results:
## t-value lower bound: 1.52 p-value lower bound: 0.065
## t-value upper bound: -1.09 p-value upper bound: 0.138
## degrees of freedom : 167.45
##
## Equivalence bounds (Cohen's d):
## low eqbound: -0.2
## high eqbound: 0.2
##
## Equivalence bounds (raw scores):
## low eqbound: -0.1663
## high eqbound: 0.1663
##
## TOST confidence interval:
## lower bound 90% CI: -0.183
## upper bound 90% CI: 0.237
##
## NHST confidence interval:
## lower bound 95% CI: -0.224
## upper bound 95% CI: 0.278
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(167.45) = -1.095, p = 0.138, given equivalence bounds of -0.166 and 0.166 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(167.45) = 0.214, p = 0.831, given an alpha of 0.05.TOSTtwo(m1 = -0.08914941, m2 = -0.11634700, sd1 = 0.7748390, sd2 = 0.8841862, n1 = 84, n2 = 87, low_eqbound_d = -0.10, high_eqbound_d = 0.10, alpha = 0.05, var.equal = FALSE)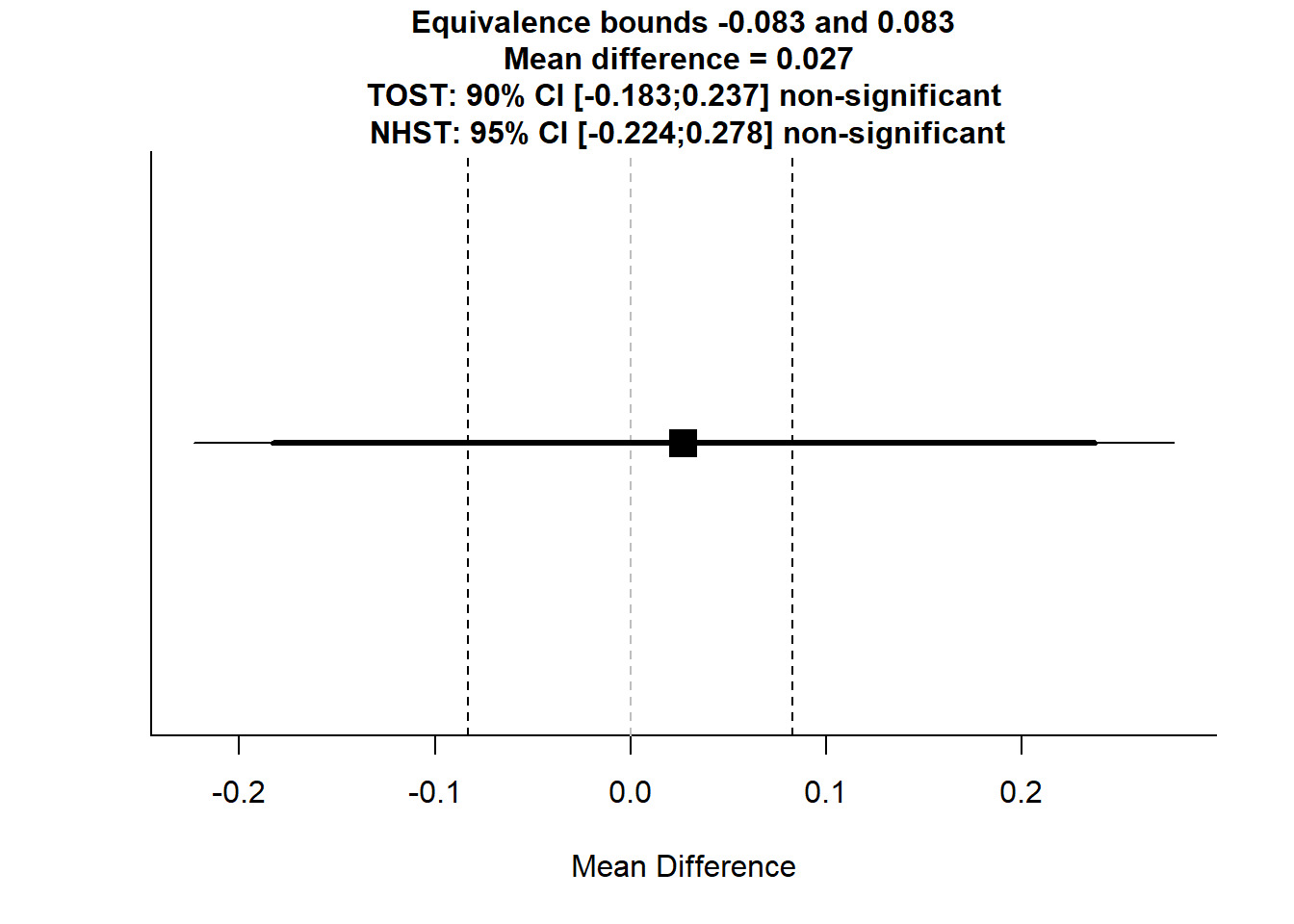
## TOST results:
## t-value lower bound: 0.869 p-value lower bound: 0.193
## t-value upper bound: -0.44 p-value upper bound: 0.330
## degrees of freedom : 167.45
##
## Equivalence bounds (Cohen's d):
## low eqbound: -0.1
## high eqbound: 0.1
##
## Equivalence bounds (raw scores):
## low eqbound: -0.0831
## high eqbound: 0.0831
##
## TOST confidence interval:
## lower bound 90% CI: -0.183
## upper bound 90% CI: 0.237
##
## NHST confidence interval:
## lower bound 95% CI: -0.224
## upper bound 95% CI: 0.278
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(167.45) = -0.440, p = 0.330, given equivalence bounds of -0.0831 and 0.0831 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(167.45) = 0.214, p = 0.831, given an alpha of 0.05.In terms of my main goal of learning how to use a package and prepare data to be analyzed by R, I mostly succeeded. I created a portion of my data file and read that in successfully, and installed TOSTER and used that for the analysis. I am quite sure that there are things I could have done more efficiently (which will be worth discussing), but I am glad I was able to get it to work.
In terms of the applied research question going into this … for both gist and verbatim risk perception, we had previously found nearly identical means for graphical and numerical presentations. We had no a priori effect size about how large a difference we’d like to detect, so I wanted to get a sense of how large a difference we could be confident didn’t exist. I was quite sure we’d be able to detect a Cohen’s d of .30, and probably .20, but I had my doubts about .10.
It turns out my intuition was somewhat overly optimstic. Despite all the lectures I’ve given on how unless you have very large n it’s very difficult to detect small to medium effect sizes, I thought that we would be able to confidently say that the effect size was not greater than .20. That turned out to be incorrect. We are able to say it’s not greater than .30, but even that test just reached significance for both gist and verbatim risk perception.
As one final test, the raw gist scale (not the verbatim one) is meaningful, and it’s of interest to see if we could detect a 1-point difference on that.
TOSTtwo.raw(m1 = 7.458824, m2 = 7.425287, sd1 = 3.815860, sd2 = 3.886866, n1 = 85, n2 = 87, low_eqbound = -1.0, high_eqbound = 1.0, alpha = 0.05, var.equal = FALSE)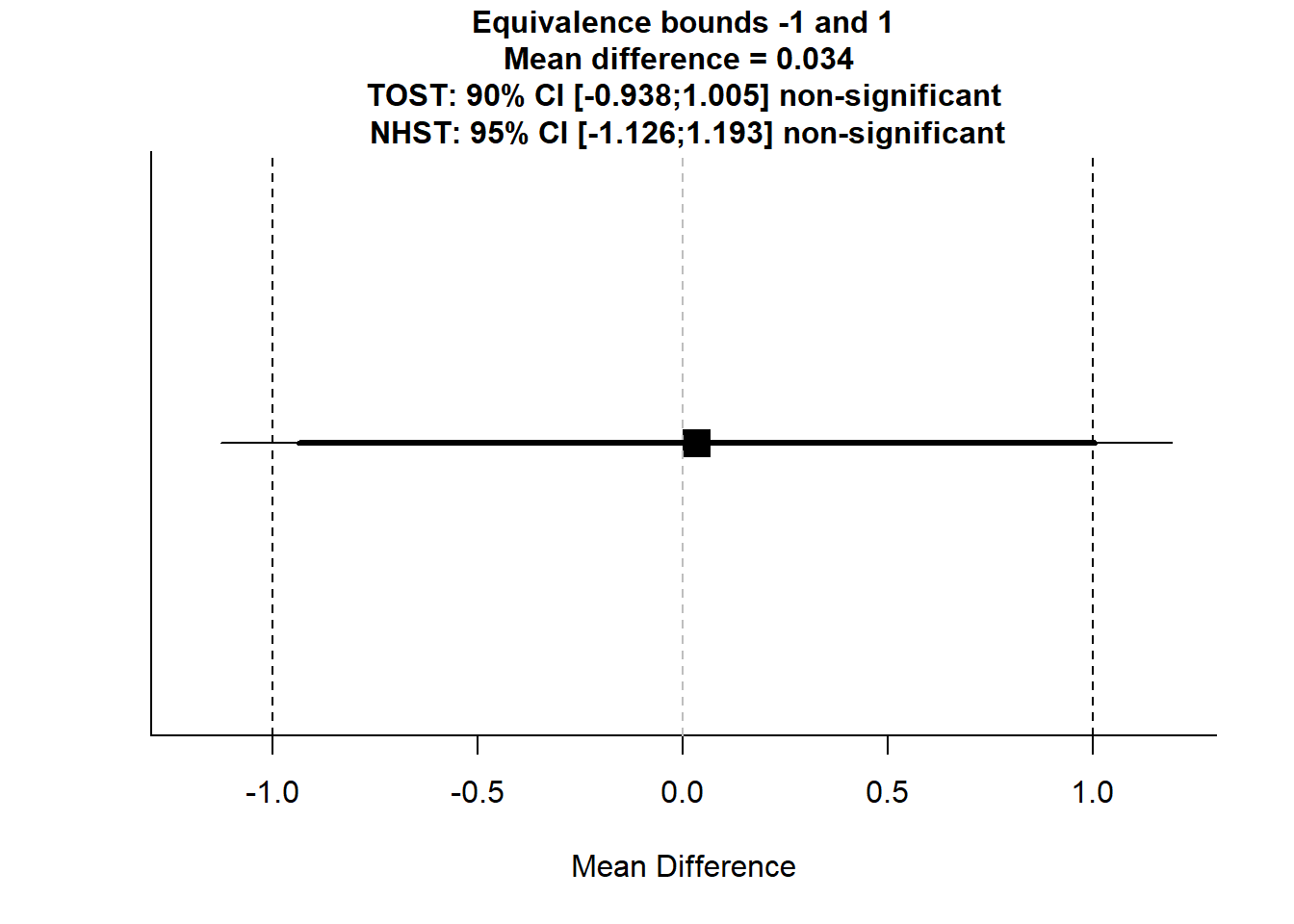
## TOST results:
## t-value lower bound: 1.76 p-value lower bound: 0.040
## t-value upper bound: -1.65 p-value upper bound: 0.051
## degrees of freedom : 170
##
## Equivalence bounds (raw scores):
## low eqbound: -1
## high eqbound: 1
##
## TOST confidence interval:
## lower bound 90% CI: -0.938
## upper bound 90% CI: 1.005
##
## NHST confidence interval:
## lower bound 95% CI: -1.126
## upper bound 95% CI: 1.193
##
## Equivalence Test Result:
## The equivalence test was non-significant, t(170) = -1.646, p = 0.0509, given equivalence bounds of -1.000 and 1.000 (on a raw scale) and an alpha of 0.05.
## Null Hypothesis Test Result:
## The null hypothesis test was non-significant, t(170) = 0.0571, p = 0.955, given an alpha of 0.05.The test wasn’t quite significant, but extremely close with p = .0509. It’s a 15-point scale so a 1-point difference isn’t that large, but it is still meaningful and it’s a little disappointing not to have stronger evidence that the effect is no greater than that.